I am sadly not sponsored by fpsVR but it IS a really good tool |
TheJebForge (talk | contribs) drives actually work with Continuously Changing |
||
| (9 intermediate revisions by 6 users not shown) | |||
| Line 62: | Line 62: | ||
<!--T:36--> | <!--T:36--> | ||
It is possible to control whether a [[MeshRenderer (Component)|MeshRenderer]] or [[SkinnedMeshRenderer (Component)|SkinnedMeshRenderer]] component casts shadows using the ShadowCastMode Enum value on the component. Changing this to 'Off' may be helpful if users wish to have some meshes cast shadows, but not all (and hence don't want to disable shadows on the relevant lights). Alternatively, there may be some performance benefits by turning off shadow casting for a highly detailed mesh and placing a similar, but lower detail, mesh at the same location with | It is possible to control whether a [[MeshRenderer (Component)|MeshRenderer]] or [[SkinnedMeshRenderer (Component)|SkinnedMeshRenderer]] component casts shadows using the ShadowCastMode Enum value on the component. Changing this to 'Off' may be helpful if users wish to have some meshes cast shadows, but not all (and hence don't want to disable shadows on the relevant lights). Alternatively, there may be some performance benefits by turning off shadow casting for a highly detailed mesh and placing a similar, but lower detail, mesh at the same location with ShadowCastMode 'ShadowOnly'. | ||
=== Culling === <!--T:18--> | === Culling === <!--T:18--> | ||
| Line 89: | Line 89: | ||
<!--T:20--> | <!--T:20--> | ||
It is possible to create additional culling systems for your worlds by selectively deactivating slots and/or disabling components depending on e.g. a user's position. Very efficient culling solutions can be created with the [[ColliderUserTracker (Component)|ColliderUserTracker component]] to detect when a user is inside a specific collider | It is possible to create additional culling systems for your worlds by selectively deactivating slots and/or disabling components depending on e.g. a user's position. Very efficient culling solutions can be created with the [[ColliderUserTracker (Component)|ColliderUserTracker component]] to detect when a user is inside a specific collider. | ||
As [[Component:ColliderUserTracker|ColliderUserTracker]], works on colliders, it cannot detect users in No-Clip. | |||
==== Specific culling considerations for collider components ==== <!--T:41--> | ==== Specific culling considerations for collider components ==== <!--T:41--> | ||
| Line 118: | Line 121: | ||
High frequency updates from the [[Update (ProtoFlux)|Update]] node, [[Fire While True (ProtoFlux)|Fire While True]], etc. should be avoided if possible if the action results in network replication. Consider replacing them with [[Drive|Drivers]]. | High frequency updates from the [[Update (ProtoFlux)|Update]] node, [[Fire While True (ProtoFlux)|Fire While True]], etc. should be avoided if possible if the action results in network replication. Consider replacing them with [[Drive|Drivers]]. | ||
=== Continuously Changing | === Continuously Changing Attribute === <!--T:28--> | ||
ProtoFlux nodes and outputs can be marked with Continuously Changing attribute which in conjunction with [[ProtoFlux:Fire On Change|Fire On Change]] (or any other Fire On X node) or [[Drive|Drives]] will make the node chain reevaluate every frame. Having any node that is marked as such in your node chain will make everything to the right of it to become Continuously Changing. Using heavy nodes (for example [[ProtoFlux:Find Child By Name|Find Child By Name]]) or really heavy node chains that contain Continuously Changing nodes, as value for Fire On Change or Drive, will force that logic to evaluate every frame, causing lag. | |||
For best performance, please avoid doing heavy computations or heavy slot lookups on Fire On X or Drives. Write the result of your heavy nodes to a [[ProtoFlux#Variables|variable]] instead, and then use the result stored in the variable. | |||
[[ProtoFlux:Continuously Changing Relay|Continuously Changing Relay]] is simply passing through the value, but since the node is marked as Continuously Changing, everything to the right of it will become Continuously Changing. | |||
=== Sample Color node === <!--T:34--> | === Sample Color node === <!--T:34--> | ||
[[Sample | [[ProtoFlux:Sample ColorX|Sample Color]] is an inherently expensive node to use as it works by rendering a small and narrow view. Best to use this sparingly. Performance cost can be reduced by limiting the range which must be rendered by using the NearClip and FarClip inputs. | ||
=== Slot Count === <!--T:31--> | === Slot Count === <!--T:31--> | ||
Slot count and packed ProtoFlux nodes don't matter much performance-wise. Loading and saving do take a hit for complex setups but this hit is not eliminated by placing the ProtoFlux nodes on one slot. Resonite still has to load and save the exact same number of components. | Slot count and packed ProtoFlux nodes don't matter much performance-wise. Loading and saving do take a hit for complex setups but this hit is not eliminated by placing the ProtoFlux nodes on one slot. Resonite still has to load and save the exact same number of components. | ||
=== Measuring ProtoFlux Performance === | |||
The runtime of a ProtoFlux [[Impulses|Impulse]] chain can be measured using [[ProtoFlux:Utc_Now|Utc Now]] and a single variable storing its value just before executing the measured code. | |||
Subtracting this value from the one evaluated just after the execution yields the duration it took to run. | |||
Take note that this does not measure indirect performance impacts like increased network load or physics updates! | |||
<gallery widths=480px heights=200px> | |||
File:Utc_Now_Demo.png|Measuring the runtime of a ProtoFlux loop. Practical applications should format the output to be more readable. | |||
</gallery> | |||
Measuring the performance impact of ProtoFlux drives is not as straightforward. | |||
The most sensible approach would be to create an [[Impulses|Impulse]] based measurement to measure the runtime of a simple [[Protoflux:Write|Write]] node connected to same expression as the drive. | |||
If you - for whatever reason - need to compute the execution time during Drive evaluation you could abuse the order of evaluations: | |||
<gallery widths=480px heights=200px> | |||
File:ProtoFlux_Drive_Performance_Measurement.png|Measuring the runtime of a ProtoFlux drive with a smoothened and formatted output. The measurement itself is very dependent on how ProtoFlux is implemented. (->not recommended) | |||
</gallery> | |||
== Profiling == <!--T:32--> | == Profiling == <!--T:32--> | ||
Latest revision as of 23:16, 7 August 2024
This is a community-generated page to help other users discover how to optimize the performance of their creations in Resonite. As with the whole Wiki, anyone is free to edit this page. However, since this page makes specific technical recommendations, it is best if information is backed up with an official source (e.g. a Discord comment from one of the Resonite development team).
Rendering
Blendshapes
Every time a blendshape changes, the vertices have to be retransformed on the entire mesh. If the majority of the mesh is not part of any blendshape, then that performance is wasted. Resonite can automatically optimize this with the "Separate parts of mesh unaffected by blendshapes" found under the SkinnedMeshRenderer component. Whether this is worth it or not varies on a case-by-case basis, so you'll have to test your before/after performance while driving blendshapes to be sure.
Any blendshape not at zero has a performance cost proportional to the number of vertices, even if the blendshape is not changing. For example, a one million vertex mesh will have a significantly higher performance impact with a blendshape at 0.01 than with the blendshape at 0. If you have a mesh with non-driven blendshapes set to anything other than zero, consider baking them.
No matter their value, when a skinned mesh is first spawned (such as when an avatar loads) every blendshape must be calculated which can result in a lag spike if there are lots of blendshapes on it; baking non-driven blendshapes will additionally help prevent that.
Materials
Some materials (notably the Fur material) are much more expensive than others.
Alpha/Transparent/Additive/Multiply blend modes count as transparent materials and are slightly more expensive because things behind them have to be rendered and filtered through them. Transparent materials use the forward rendering pipeline, so they don't handle dynamic lights as consistently. Opaque and Cutout blend modes on PBS materials use the deferred rendering pipeline, and handle dynamic lights better.
Texture Dimensions
Square textures with pixel dimensions of a power of two (2, 4, 8, 16, 32, 64, 128, 512, 1024, 2048, 4096, etc) are more efficiently handled in VRAM.
Texture Atlasing
If you have a number of different materials of the same type, consider atlasing (combining multiple textures into one larger texture). Even if different parts of your mesh use different settings, the addition of maps can let you combine many materials into one. Try to avoid large empty spaces in the resulting atlas, as they can waste VRAM.
Places where atlasing doesn't help:
- If you need a different material all together, e.g. a Fur part of a mostly PBS avatar.
- If you need part of your avatar to have Alpha blend, but the majority is fine with Opaque or Cutout.
Procedural vs Static Assets
If you are not driving the parameters of a procedural mesh, then you can save performance by baking it into a static mesh. Procedural meshes and textures are per-world. This is because the procedural asset is duplicated with the item. Static meshes and textures are automatically instanced across worlds so there's only a single copy in memory at all times, and do not need to be saved on the item itself.
GPU Mesh Instancing
If there are multiple instances of the same static mesh/material combination, they will be instanced (on most shaders). This can significantly improve performance when rendering multiple instances of the same object, e.g. having lots of trees in the environment. Note that SkinnedMeshRenderers are not eligible for GPU instancing.
Mirrors and Cameras
Mirrors and cameras can be quite expensive, especially at higher resolutions, as they require additional rendering passes. Mirrors are generally more expensive than cameras, as they require two additional passes (one per eye).
The performance of cameras can be improved by using appropriate near/far clip values and using the selective/exclusive render lists. Basically, avoid rendering what you don't need to.
It's good practice to localize mirrors and cameras with a ValueUserOverride so users can opt in if they're willing to sacrifice performance to see them.
As a rule of thumb, a 1024x1024 mirror can work well on an integrated GPU, while a 4096x4096 mirror (normally fine on a dedicated GPU) tends to ruin performance. If you're adding quality options to your world, then adjusting camera and mirror resolutions accordingly will help a lot.
Reflection Probes
Baked reflection probes are quite cheap, especially at the default resolution of 128x128. The only real cost is the VRAM used to store the cube map.
Real-time reflection probes are extremely expensive, and are comparable to six cameras.
Lighting
Light impact is proportional to how many pixels a light shines on. This is determined by the size of the visible light volume in the world, regardless of much geometry it affects. Short range or partially occluded lights are therefore cheaper.
Lights with shadows are much more expensive than lights without. In deferred shading, shadow-casting meshes still need to be rendered once or more for each shadow-casting light. Furthermore, the lighting shader that applies shadows has a higher rendering overhead than the one used when shadows are disabled.
Point lights with shadows are very expensive, as they render the surrounding scene six times. If you need shadows try to keep them restrained to a spot or directional light.
It is possible to control whether a MeshRenderer or SkinnedMeshRenderer component casts shadows using the ShadowCastMode Enum value on the component. Changing this to 'Off' may be helpful if users wish to have some meshes cast shadows, but not all (and hence don't want to disable shadows on the relevant lights). Alternatively, there may be some performance benefits by turning off shadow casting for a highly detailed mesh and placing a similar, but lower detail, mesh at the same location with ShadowCastMode 'ShadowOnly'.
Culling
'Culling' refers to not processing, or at least not rendering, specific parts of a world to reduce performance costs.
Frustrum culling
Resonite automatically performs frustum culling, meaning objects outside of the field of view will not render (e.g. objects behind a user). With frustrum culling, there is some cost associated with calculating visibility, but it is generally constant for each mesh. The detection process relies on each object's bounding box, which is essentially an axis-aligned box that fully wraps around the entire mesh. Therefore the mesh complexity is irrelevant (save for the initial calculation of its bounds or, in case of skinned meshes with some calculation modes, the number of bones). There are a few considerations to optimizing content to work best with this system.
- The cost of checking for whether objects should be culled by this system scales with the number separate active meshes. This means it can work together with user-made culling systems (see below) which can reduce the number of active meshes which must be tested.
- If any part of a mesh is determined to be visible due to the bounding box calculation, the entire mesh must be rendered - Resonite cannot only render parts of a mesh.
- As such, sometimes it makes sense to separate a large mesh into smaller pieces if the whole mesh would not normally be visible all at once. World terrain meshes may be good candidates for splitting into separate submeshes.
- On the other hand, in some situations it is better to combine meshes which will generally be visible at the same time. Even though combining meshes with multiple materials does not directly save on rendering costs, it does save on testing for whether meshes should be culled. If multiple meshes are baked into a single mesh, the bounding box testing only needs to be performed once for that combined mesh. This is effectively Resonite's version of the static mesh batching which occurs in Unity.
Note that SkinnedMeshRenderer components have multiple modes for bounds calculation which impose different performance costs. The calculation mode is indicated by the BoundsComputeMethod on each SkinnedMeshRenderer component.
Staticis a very cheap method based on the mesh alone. This does not require realtime computation, so ideally use this if possible.FastDisjointRootApproximatefirst merges all bones into disjoint groups (any overlapping bones are merged into a single one) to reduce overall number of bones. It then uses those to approximate bounds in realtime. Fastest realtime method, recommended if parts of a mesh are being culled when using `Static`.MediumPerBoneApproximatecomputes mesh bounds from bounds of every single bone. More accurate, but also much slower.SlowRealtimeAccurateuses actual transformed geometry, requiring the skinned mesh to be processed all the time. Very heavy, but will respect things like blendshapes in addition to bones.Proxyis slightly different from the others, but also potentially very cheap. It relies on the bounding box calculated for another SkinnedMeshRenderer referenced in the ProxyBoundsSource field. Useful in cases where you have a large main mesh and you need the visiblity of smaller meshes to be linked to it.
User-made culling systems
It is possible to create additional culling systems for your worlds by selectively deactivating slots and/or disabling components depending on e.g. a user's position. Very efficient culling solutions can be created with the ColliderUserTracker component to detect when a user is inside a specific collider.
As ColliderUserTracker, works on colliders, it cannot detect users in No-Clip.
Specific culling considerations for collider components
Avoid performing manual culling of colliders in such a way that they are activated/deactivated very often. Collider performance impact works differently than for rendered meshes; performance costs for colliders are already heavily optimized as they are only checked when they're relevant. Toggling them on and off regularly can disrupt this under-the-hood optimization process and may even be more expensive.
ProtoFlux
Less ProtoFlux is not always better! It's more important to make your calculations do less work than it is to do them in a smaller space. Users should also not feel pressured to avoid using ProtoFlux because they believe using 'only components' is somehow more optimal. There are many cases where specific components are a better solution than using several ProtoFlux nodes and vice-versa, the decision mainly comes down to using the best tool for the job.
Writes and Drivers
Changing the value of a Sync will result in network traffic, as that change to the data model needs to be sent to the other users in the session. ValueUserOverride does not remove this network activity, as the overrides themselves are Syncs.
Exceptions:
- Drivers compute things locally for every user, and do not cause network traffic
- "Self Driven values" (A ValueCopy with Writeback and the same source and target) are also locally calculated, even if you use the Write node to change the value. Do note, Stores or Locals can serve this functionality in a more optimized way.
- If multiple writes to a value occur in the same update, only the last value will be replicated over the network.
Generally it's cheaper to perform computations locally and avoid network activity, but for more expensive computations it's better to have one user do it and sync the result.
Dynamic Variables and Impulses
Dynamic Variables are extremely efficient and can be used without concern for performance, however creating and destroying Dynamic Variable Spaces can be costly and should be done infrequently. Care should also be taken when driving dynamic variables; while this is possible, you must ensure that EVERY instance of the same DynamicValueVariable or DynamicReferenceVariable is driven as well.
Dynamic Impulses are also extremely efficient, especially if you target them at a slot close to their receiver.
Frequent Impulses
High frequency updates from the Update node, Fire While True, etc. should be avoided if possible if the action results in network replication. Consider replacing them with Drivers.
Continuously Changing Attribute
ProtoFlux nodes and outputs can be marked with Continuously Changing attribute which in conjunction with Fire On Change (or any other Fire On X node) or Drives will make the node chain reevaluate every frame. Having any node that is marked as such in your node chain will make everything to the right of it to become Continuously Changing. Using heavy nodes (for example Find Child By Name) or really heavy node chains that contain Continuously Changing nodes, as value for Fire On Change or Drive, will force that logic to evaluate every frame, causing lag.
For best performance, please avoid doing heavy computations or heavy slot lookups on Fire On X or Drives. Write the result of your heavy nodes to a variable instead, and then use the result stored in the variable.
Continuously Changing Relay is simply passing through the value, but since the node is marked as Continuously Changing, everything to the right of it will become Continuously Changing.
Sample Color node
Sample Color is an inherently expensive node to use as it works by rendering a small and narrow view. Best to use this sparingly. Performance cost can be reduced by limiting the range which must be rendered by using the NearClip and FarClip inputs.
Slot Count
Slot count and packed ProtoFlux nodes don't matter much performance-wise. Loading and saving do take a hit for complex setups but this hit is not eliminated by placing the ProtoFlux nodes on one slot. Resonite still has to load and save the exact same number of components.
Measuring ProtoFlux Performance
The runtime of a ProtoFlux Impulse chain can be measured using Utc Now and a single variable storing its value just before executing the measured code. Subtracting this value from the one evaluated just after the execution yields the duration it took to run. Take note that this does not measure indirect performance impacts like increased network load or physics updates!
-
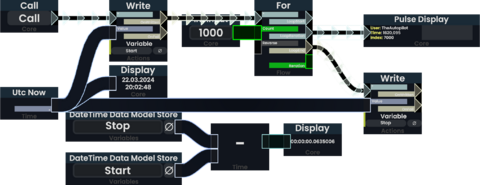 Measuring the runtime of a ProtoFlux loop. Practical applications should format the output to be more readable.
Measuring the runtime of a ProtoFlux loop. Practical applications should format the output to be more readable.

Measuring the performance impact of ProtoFlux drives is not as straightforward. The most sensible approach would be to create an Impulse based measurement to measure the runtime of a simple Write node connected to same expression as the drive.
If you - for whatever reason - need to compute the execution time during Drive evaluation you could abuse the order of evaluations:
-
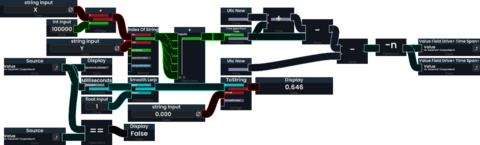 Measuring the runtime of a ProtoFlux drive with a smoothened and formatted output. The measurement itself is very dependent on how ProtoFlux is implemented. (->not recommended)
Measuring the runtime of a ProtoFlux drive with a smoothened and formatted output. The measurement itself is very dependent on how ProtoFlux is implemented. (->not recommended)

Profiling
If you're working on a new item that might be expensive, consider profiling it:
- The Debug menu you can find in Home tab of the Dash has many helpful timings
- SteamVR has a "Display Performance Graph" that can show GPU frametimes. This can also be shown in-headset from a toggle in the developer settings (toggle "Advanced Settings" on in the settings menu)
- fpsVR is a paid SteamVR tool that gives a lot of information about CPU and GPU timings, vram/ram usage and other metrics that can be very useful when profiling inside of VR.